How Developer Marketing Teams Create Original Content With AI
Developers spot AI-generated fluff instantly. Here's how dev tool companies use real community data — from Reddit, Hacker News, and GitHub — to fuel AI content creation that actually resonates.
If you're marketing a developer tool, API, or SDK, you already know: developers are the hardest audience to create content for. They spot AI-generated fluff from a paragraph away. They skip your landing page and go straight to the docs. They trust a Reddit thread over a case study.
And yet every developer marketing team faces the same pressure in 2026: ship more content, faster, with AI. The problem? The output all sounds the same.
That's not a tools problem. It's a data problem.
Large language models are trained on the internet's existing corpus. When you prompt ChatGPT or Claude to "write a blog post about feature flags," you get a synthesis of everything already published about feature flags. It's competent, grammatically correct, and utterly indistinguishable from what your competitor published last Tuesday.
Google knows this. Their information gain patent — granted in 2022 — describes a scoring system that measures how much new information a piece of content adds beyond what's already available. Content that simply reorganizes existing knowledge scores low. Content built on original data, unique perspectives, and first-party insights scores high.
Here's the uncomfortable math: if an AI can answer a question by synthesizing existing sources, your content adding the same answer contributes zero information gain. AI models are trained on the average of the internet, so their raw output is mathematically average. For developer audiences — who are already more skeptical of marketing content — generic AI output is dead on arrival.
But there's a workaround that most developer marketing teams haven't discovered yet: use social signal tracking data as the input layer for your content system.
Your developers, users, and community are generating original, unscripted insights about your API, your SDK, your CLI, and your competitors every single day — on Reddit, Hacker News, GitHub, Stack Overflow, Twitter, DEV, podcasts, and newsletters. This data is unique to your brand. No competitor has it. No LLM was trained on it in this specific combination.
When you pipe this data into an AI content workflow, the output isn't generic anymore. It's grounded in real conversations, real sentiment, and real language that only your brand has access to.
This guide shows you exactly how to build that system — specifically for companies that serve developers.
Before we build the solution, let's understand why this problem is especially acute for developer tool companies.
Google's Quality Rater Guidelines, updated in 2025, specifically instruct raters to mark mass-produced pages with no original content as "Lowest" quality. Google's algorithms increasingly penalize content that lacks genuine experience signals, original data, and expert perspective — and pure AI output rarely demonstrates any of these qualities.
This isn't theoretical. Google reported that their 2024 spam update reduced the amount of low-quality, unoriginal content in search results by 45%. Developer audiences are even more ruthless than Google — they'll close the tab the moment content reads like a machine wrote it.
The root cause is simple: LLMs can only remix what already exists. They can't conduct original research, interview customers, or observe patterns in your specific market. When everyone uses the same models with similar prompts, the output converges.
Developer marketing has a unique challenge that makes generic AI content creation especially dangerous:
Developers live in communities, not funnels. Your ICP isn't scrolling LinkedIn waiting for your next thought leadership post. They're deep in Reddit threads debating your SDK vs. a competitor's. They're filing GitHub issues. They're asking on Stack Overflow whether your API handles edge cases correctly. They're reading Hacker News comments about your latest release.
Developers trust peers over brands. A positive Reddit comment from a fellow engineer carries more weight than any blog post your marketing team writes. Developer marketing that works is grounded in these real community conversations — not in what an LLM thinks developers want to hear.
The platforms that matter are different. For developer tools, the highest-signal sources are Reddit, Hacker News, GitHub, Stack Overflow, DEV, and Discord — not the B2C channels that dominate traditional SaaS content marketing. If your content strategy doesn't reflect what's happening on these platforms, you're writing in a vacuum.
This is exactly why community mention data is so powerful for dev tool companies. It's the bridge between what your community is actually saying and the content your marketing team produces.
Google's information gain patent describes a mechanism for calculating how much unique information a document provides beyond what a user has already seen. Many SEO professionals believe it — or systems like it — now plays a direct role in ranking decisions.
The concept is straightforward: after a user views several search results on a topic, Google can calculate which remaining documents offer genuinely new information versus which ones simply repeat the consensus. Documents with high information gain scores get promoted. Documents that just repackage existing knowledge get buried.
The types of content that create information gain include: original data from surveys or proprietary sources, expert insights, unique perspectives on topics, and real-world examples. Notice what all of these have in common — they require inputs that don't exist in the LLM's training data.
Here's the key insight: your brand mentions are a proprietary dataset.
Every week, developers post candid feedback about your tool on Reddit. Engineers discuss your API on Hacker News. Prospects compare your SDK to alternatives on Twitter. Open-source contributors file issues and feature requests on GitHub. Industry newsletters mention your latest release. Podcast hosts debate whether your approach to the problem is the right one.
This data has three properties that make it uniquely valuable for content creation:
- It's original. No one else has your specific combination of mentions, sentiment patterns, and community conversations across developer platforms.
- It's current. Brand mentions reflect what developers are saying right now, not what was true when the LLM was last trained.
- It's authentic. These are real engineers using real language to describe real experiences — the exact "experience signals" that Google's E-E-A-T framework rewards.
The problem is that most developer marketing teams treat brand mention tracking as a reactive tool — check for fires, respond to complaints, maybe share a positive mention in Slack. Very few have realized that mention data is a content creation asset.
Let's fix that.
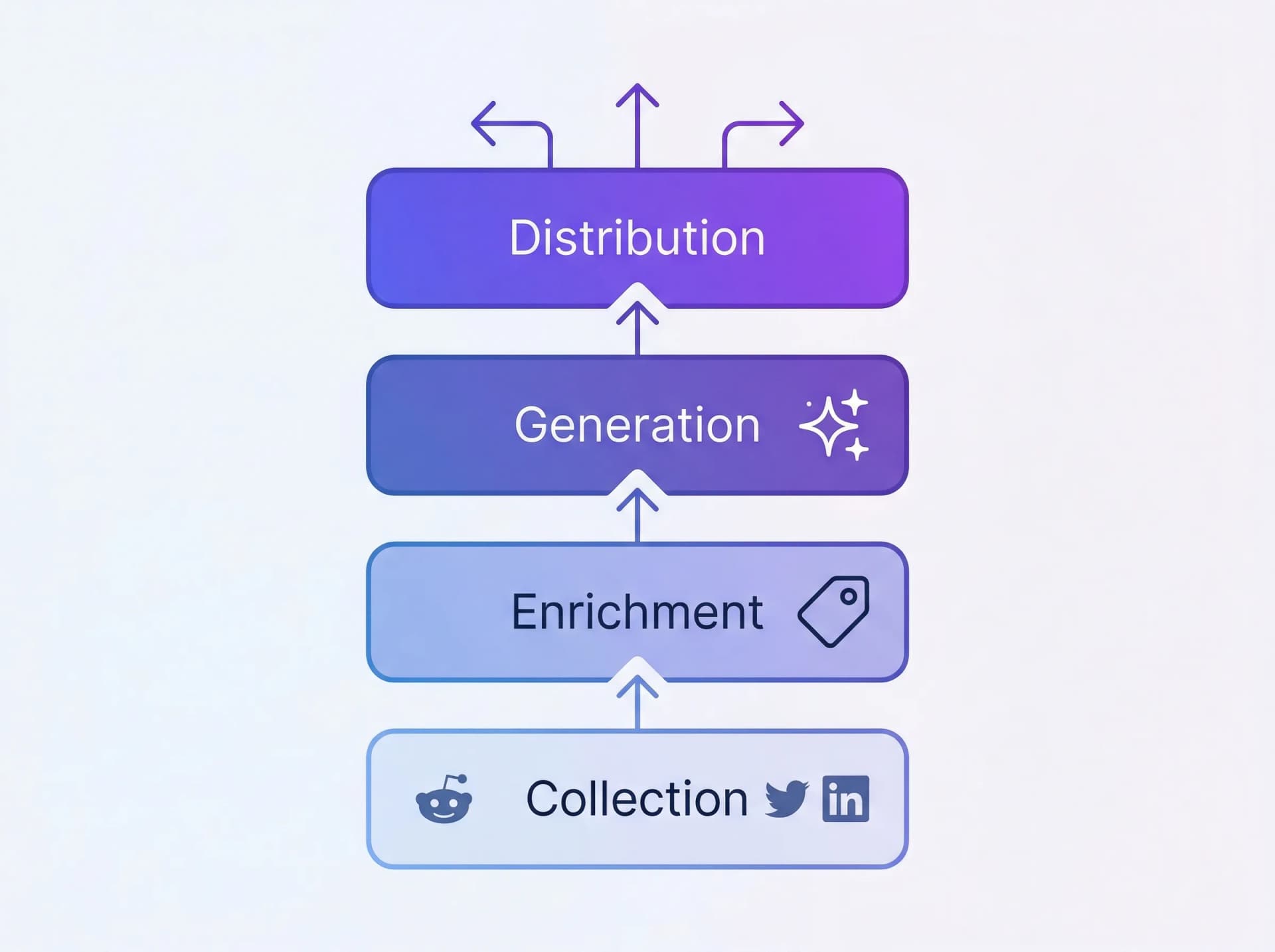
The system has four layers:
- Collection — Brand mentions from 15+ platforms, pre-labeled with sentiment, relevance, and source
- Enrichment — Categorize mentions by content type potential, tag themes, extract patterns
- Generation — AI drafts grounded in real mention data for blog posts, social, newsletters, and case studies
- Distribution — Publish across channels, track performance, feed learnings back into collection
Each layer is automated or semi-automated. The human role shifts from "write content from scratch" to "curate, edit, and approve content grounded in real developer conversations."
Let's build each layer.
The foundation is structured access to your brand mentions across every developer platform that matters. You need:
- Developer platform coverage: Reddit, Hacker News, GitHub, Stack Overflow, DEV, Twitter/X, LinkedIn, YouTube, Bluesky, podcasts, newsletters, and more
- Structured data: Each mention should include the text, source platform, author metadata, sentiment, relevance score, engagement metrics, and a timestamp
- A social listening API: To build automated content creation pipelines, you need programmatic access — not just a dashboard you check manually
The Octolens API — a social listening API built for developer tool companies — returns structured JSON for every mention. Here's how to pull your recent mentions:
curl https://api.octolens.com/v1/mentions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"filters": {
"keyword": [123],
"source": ["reddit", "twitter", "linkedin", "hackernews"],
"startDate": "2026-03-01T00:00:00Z"
}
}'
Each mention comes back with structured metadata:
{
"id": 984210,
"source": "reddit",
"title": "Best developer tools for API monitoring in 2026?",
"body": "Just tried YourSDK and it completely changed how we handle monitoring...",
"author": "developer_mike",
"authorName": "Mike Chen",
"url": "https://reddit.com/r/SaaS/comments/xyz789",
"sentimentLabel": "Positive",
"relevanceScore": 0,
"tags": ["own_brand_mention", "user_feedback"],
"timestamp": "2026-03-08T14:23:00Z",
"language": "en"
}
The key fields for content creation are:
body— The raw text of what someone said. This is your original data.sentimentLabel— Pre-labeled as Positive, Negative, or Neutral. Saves you from manual classification.relevanceScore— AI-scored relevance to your brand (0 = High, 1 = Medium, 2 = Low). Filter out noise before it enters your content pipeline.source— Which platform the mention came from. Different platforms yield different content types.tags— AI-assigned categories likeuser_feedback,buy_intent,competitor_mention, and more. Use these to route mentions to the right content workflows.
For a more automated setup, configure a webhook so mentions flow into your system as they're detected:
// Express.js webhook receiver
app.post('/webhooks/octolens', async (req, res) => {
const mention = req.body;
// Store in your database
await db.mentions.create({
source: mention.source,
body: mention.body,
title: mention.title,
sentiment: mention.sentimentLabel,
relevance: mention.relevanceScore,
tags: mention.tags,
processed: false, // Flag for content pipeline
created_at: mention.timestamp,
});
res.status(200).send('OK');
});
If you're using Claude or another MCP-compatible AI agent, you can skip the API entirely and let your AI query mentions directly through the Octolens MCP server:
"Pull all positive Reddit mentions about our brand from the last 7 days with a relevance score above 0.8 and at least 10 upvotes."
The MCP server lets AI agents access your mention data natively — your agent can query recent mentions, filter by sentiment or platform, and use the data in its reasoning without building a custom integration.
For a developer tool content system, you want three keyword categories:
- Brand keywords — Your tool name, SDK name, CLI name, common misspellings, GitHub repo name
- Competitor keywords — Competitor names, "X alternatives," "X vs Y," competitor GitHub repos
- Category keywords — The developer problems you solve, the tools in your space, industry trends (e.g., "API monitoring," "feature flags," "CI/CD pipeline")
Each category feeds different content types. Brand mentions fuel case studies, technical deep-dives, and changelog content. Competitor mentions fuel comparison posts and migration guides. Category mentions fuel thought leadership, tutorials, and educational content.
Raw mentions are noisy. Before they become content inputs, they need to be categorized by their content potential.
Build a simple classification step that tags each mention with the type of content it could fuel. Here's a prompt you can use with any LLM:
You are a content strategist for a developer tool company.
Analyze the following brand mention and classify it into
one or more content categories:
Mention: "{mention_body}"
Source: {platform}
Sentiment: {sentimentLabel}
Tags: {tags}
Categories:
- TESTIMONIAL: Developer expressing satisfaction or praising the tool
- API_FEEDBACK: Developer commenting on API design, DX, or SDK quality
- USE_CASE: Developer describing how they use the tool in their stack
- COMPARISON: Developer comparing your tool to alternatives
- INTEGRATION_REQUEST: Developer asking for a new integration or platform support
- DOCS_GAP: Developer struggling with documentation or onboarding
- MIGRATION_STORY: Developer describing switching from a competitor
- TREND: Developer discussing an industry trend related to your space
- OBJECTION: Developer expressing doubt or concern about the tool
Return: category, confidence score (0-1),
and a one-line summary of the content angle.
Here's a Python script that processes your stored mentions nightly:
import anthropic
import json
client = anthropic.Anthropic()
def enrich_mention(mention):
"""Classify a developer tool mention by content potential."""
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=300,
messages=[{
"role": "user",
"content": f"""Classify this brand mention for content potential.
Mention: "{mention['body']}"
Source: {mention['source']}
Sentiment: {mention['sentimentLabel']}
Tags: {json.dumps(mention['tags'])}
Return JSON only:
{{
"categories": ["TESTIMONIAL", "USE_CASE"],
"confidence": 0.85,
"content_angle": "Customer describing time savings from automated monitoring",
"quotable": true,
"suggested_formats": ["blog_post", "social_proof", "newsletter"]
}}"""
}]
)
return json.loads(response.content[0].text)
# Process unprocessed mentions
unprocessed = db.mentions.find({"processed": False})
for mention in unprocessed:
enrichment = enrich_mention(mention)
db.mentions.update(mention["id"], {
"content_categories": enrichment["categories"],
"content_angle": enrichment["content_angle"],
"quotable": enrichment["quotable"],
"suggested_formats": enrichment["suggested_formats"],
"processed": True,
})
After enrichment, you'll have a tagged database of mentions. Now create a content backlog view that looks something like this:
- Use Cases (34 mentions) — Top angle: "Automated Slack alerts when devs mention our API on Reddit" → High priority
- API Feedback (28 mentions) — Top angle: "Webhook latency improved after v2 migration" → High priority
- Comparisons (15 mentions) — Top angle: "Switched from Brand24 — better developer experience" → Medium priority
- Migration Stories (12 mentions) — Top angle: "How we migrated from Mention to an API-first setup" → Medium priority
- Docs Gaps (8 mentions) — Top angle: "SDK quickstart guide needs Python example" → High priority (for docs + content)
This backlog is your editorial calendar — driven by real developer conversations, not guesswork.
This is where the magic happens. Instead of asking AI to "write a blog post about brand monitoring," you give it specific, real-world data to work with.
Input: 20-50 mentions from the past week, filtered by relevance > 0.7
Prompt structure:
Here are {count} real mentions of our developer tool from the past
week across Reddit, Hacker News, GitHub, Stack Overflow, and Twitter:
{mention_data}
Write a weekly developer community roundup blog post that:
1. Identifies the 3-4 key themes across these mentions
2. Highlights specific conversations (paraphrased, with links)
3. Shares our engineering team's response or perspective on each theme
4. Includes data: total mentions, sentiment breakdown, top platforms
5. Ends with what we're building based on this developer feedback
Tone: Transparent, technical, not corporate.
Write like an engineering lead updating the community.
Why this works for SEO: Every roundup is unique because the underlying data changes weekly. No competitor can write this post because they don't have your mention data. This is textbook information gain — every issue adds new information to the corpus.
Example output structure:
This Week in [Tool]: Developer Community Pulse #47
1,247 mentions across 8 platforms. 78% positive sentiment. Here's what you told us this week.
Theme 1: SDK Performance on Large Repos We saw 12 conversations this week about SDK performance at scale. A developer in r/programming noted that...
Theme 2: The MCP Server Is Finding Its Audience Since launching our MCP server, we've seen a steady stream of developers connecting their AI agents to our API...
Input: Competitor mentions + your brand mentions, filtered by COMPARISON category
Here are real user conversations comparing our product to {competitor}:
Users who prefer us:
{pro_mentions}
Users who prefer them:
{con_mentions}
Neutral comparisons:
{neutral_mentions}
Write an honest comparison blog post "[Brand] vs {competitor}" that:
1. Acknowledges what {competitor} does well (from real user quotes)
2. Highlights where we win (from real user quotes)
3. Recommends who should use which tool
4. Uses actual engagement data to show which points resonate most
5. Doesn't trash the competitor — let the user quotes speak
Include a comparison table based on the specific features users mention most.
Why this works: Comparison posts driven by actual developer sentiment are categorically different from the typical "we're better at everything" competitor pages. They contain original perspectives (real developer opinions), they're more trustworthy (balanced view), and they address the specific technical criteria engineers actually evaluate when choosing tools.
Input: Pain-point mentions + use-case mentions from the same topic area
Here are real conversations from developers experiencing {problem}:
Pain points (before finding a solution):
{pain_mentions}
Solutions (how developers solved it):
{solution_mentions}
Write a blog post titled "How DevRel Teams Are Solving {Problem}
in 2026" that:
1. Opens with a real developer scenario (synthesized from pain mentions)
2. Quantifies the cost of the problem (using engagement data as
a proxy for how much developers care)
3. Walks through the solution approaches engineers are actually discussing
4. Shows specific examples of results (from positive mentions)
5. Includes direct links to source conversations where relevant
This should feel like a technical research report, not a sales pitch.
Input: Top 10 most-engaged mentions from the past week
These are the 10 highest-engagement mentions of our brand this week:
{top_mentions_with_engagement_data}
Write a newsletter issue that:
1. Leads with the most surprising or interesting mention
2. Groups mentions by theme (max 3 themes)
3. For each theme, provides our take or a specific action we're taking
4. Includes exact engagement numbers (47 upvotes, 12 comments, etc.)
5. Closes with a question to the reader
Format: Short paragraphs, conversational, ~500 words total, scannable.
Input: Testimonial-tagged mentions, filtered by engagement > threshold
For developer tool companies, the social proof that matters most isn't LinkedIn endorsements — it's GitHub stars, HN upvotes, Reddit threads with 50+ comments, and Stack Overflow answers that reference your tool. This pattern turns those into distributable content.
Here are 5 real developer testimonials from this week:
{testimonial_mentions}
For each, create:
1. A Twitter/X post (< 280 chars) that highlights the key quote
2. A LinkedIn post (3-4 paragraphs) that tells the technical story
behind the mention
3. A one-line website testimonial with attribution
Rules:
- Paraphrase rather than direct quote (unless you have permission)
- Include the platform and context (e.g., "from a Hacker News thread
about API monitoring tools")
- Add a relevant technical takeaway or lesson
- Never be salesy — let the developer's words do the work

With this system running, your weekly content workflow becomes:
Monday (30 minutes): Review enriched mention backlog from the past week. Pick 2-3 content angles with the highest mention count and engagement. Assign them to content patterns (roundup, comparison, story, etc.).
Tuesday-Wednesday (2 hours): Run the AI generation prompts with real mention data. Edit the output: add your perspective, verify quotes, add internal links. This is where human judgment matters — the AI provides the scaffolding grounded in data, you add the voice and editorial decisions.
Thursday (30 minutes): Schedule social posts derived from the same mention data. Queue newsletter content.
Friday (15 minutes): Review content performance from the previous week. Note which mention-driven pieces performed best. Adjust next week's keyword focus if needed.
Total time: ~3.5 hours per week for 2-3 blog posts, 5-10 social posts, and 1 newsletter.
Compare this to the traditional developer marketing approach: staring at a blank page, brainstorming topics, researching from scratch, writing without unique data. That process takes 4-6 hours per blog post and produces content that sounds like everyone else's.
Track which content types perform best and feed that back into your enrichment layer:
# Weekly performance review
high_performers = db.content.find({
"published_at": {"$gte": last_week},
"pageviews": {"$gte": 500},
})
for post in high_performers:
# Tag the source mentions as "high-performing source"
for mention_id in post["source_mentions"]:
db.mentions.update(mention_id, {
"led_to_high_performing_content": True,
})
# Over time, this reveals which mention patterns
# (platform, sentiment, engagement level, category)
# produce the best content
Here's what a month looks like when you run this system for a developer tool company with ~500 mentions per week:
Week 1:
- Blog: "5 Things Developers Taught Us This Week About Our SDK" (community roundup)
- Newsletter: Top 3 developer mentions + engineering team commentary
- Social: 3 posts featuring developer testimonials from Reddit and HN
Week 2:
- Blog: "Sentry vs Datadog: What Developers Actually Say" (data-backed comparison)
- Blog: "Why Backend Teams Are Switching to API-First Monitoring" (trend piece from category mentions)
- Social: 5 posts highlighting specific integration stories from Reddit threads
Week 3:
- Blog: "How [Customer]'s DevRel Team Caught a Breaking Change 5 Minutes After Deployment" (case study from mention data)
- Newsletter: Monthly sentiment report + developer community trends
- Social: 3 posts addressing common migration concerns (driven by negative/neutral mentions)
Week 4:
- Blog: "The State of Developer Tools: What 2,000 Community Mentions Reveal This Month" (data-backed thought leadership)
- Blog: "Reddit vs Hacker News vs Stack Overflow: Where Developer Tools Get Mentioned Most" (original data analysis)
- Social: 4 posts with mention statistics and developer insights
That's 6 blog posts, 4 newsletters, and 15+ social posts per month — all built on original developer community data that no competitor can replicate.
For developer marketing teams that want maximum leverage, here's the fully automated version using content automation platforms you probably already know.
If you're already using Claude for content, the MCP integration is the most natural approach:
Prompt to Claude (with Octolens MCP connected):
"Pull all Reddit and Hacker News mentions from the last 7 days
with positive sentiment and relevance above 0.8.
Group them by theme. For the top 3 themes, draft a blog post
outline that includes:
- A specific data point from the mentions
- At least 2 paraphrased user quotes
- An original take from our team's perspective
- A clear content angle that hasn't been covered by competitors"
Claude queries the MCP server, gets structured mention data, and produces content outlines grounded in your real data — all in one step.
Trigger: Octolens webhook (new mention detected)
↓
Filter: relevance_score > 0.7 AND sentiment != "neutral"
↓
Route by content_category:
├── TESTIMONIAL → Add to testimonial database
├── PAIN_POINT → Add to problem/solution queue
├── COMPARISON → Add to competitor content queue
└── USE_CASE → Add to case study pipeline
↓
Weekly aggregation trigger (every Monday):
↓
For each queue with 5+ items:
→ Generate content draft via Claude API
→ Send draft to Slack for review
→ On approval, publish to CMS
Most SaaS content marketing strategies produce diminishing returns. You publish a blog post, it ranks for a while, traffic decays. The next post starts from zero.
A mention-driven content system compounds because:
The data gets richer over time. More developer mentions = more content angles = more original insights. After 6 months, you have historical trend data about your developer community that no one else has.
Content performance feeds back into collection. You learn which topics resonate with developers, which sharpens your keyword tracking, which produces better mention data, which creates better content.
Search engines reward the pattern. Consistently publishing content with original data, real developer quotes, and unique perspectives builds topical authority. Google's systems learn that your site is a primary source for your category, not a content aggregator. This is information gain SEO in practice.
Competitors can't copy it. They don't have your mention data. They can copy your content format, but not the underlying community data that makes it unique. Their AI-generated content remains generic; yours is grounded in proprietary developer intelligence.
It serves multiple channels simultaneously. The same mention data feeds blog posts, changelogs, newsletters, social posts, case studies, DevRel talks, and product feedback. One input, many outputs.
You don't need to build the full content marketing automation pipeline on day one. Here's the minimum viable version:
Step 1 (5 minutes): Sign up for Octolens and set up keyword tracking for your tool name, top 2 competitors, and 1 category keyword (e.g., "API monitoring" or "feature flags").
Step 2 (10 minutes): Configure a webhook to pipe mentions into a Google Sheet, Notion database, or Airtable. Use a tool like n8n or Make for zero-code setup. Or use the Octolens API directly if you prefer code.
Step 3 (15 minutes): At the end of your first week, export the mentions. Paste them into Claude or ChatGPT with this prompt:
Here are [X] real developer mentions of my tool from the past week.
Identify the 3 strongest content angles and write a draft
blog post outline for each, citing specific mentions as evidence.
That's it. You now have three content ideas grounded in original community data, with real developer quotes and specific examples baked in. No other developer marketing team in your space has this.
Scale from there.
The AI content creation crisis is real, but it's not about the AI — it's about the inputs. When every developer tool company feeds the same public knowledge into the same models, the output converges on mediocrity. And developers — your most important audience — will ignore it.
Brand mention tracking data is the unlock. It's proprietary, it's current, it's authentic, and it's structured for programmatic use via API. When you feed it into an AI content workflow, you get something that doesn't exist anywhere else: original developer insights at scale.
The developer marketing teams that figure this out first will own their category's content landscape. The teams that keep prompting AI with generic instructions will keep publishing content that sounds like everyone else's.
Your developer community is already generating the raw material — on Reddit, Hacker News, GitHub, and Stack Overflow. Build the system that turns it into your unfair advantage.